![[in]genios](http://images.squarespace-cdn.com/content/v1/51c861c1e4b0fb70e38c0a8a/48d2f465-eaf4-4dbc-a7ce-9e75312d5b47/logo+final+%28blanco+y+rojo%29+crop.png?format=1500w)
Analysis of Student Depression: Associated Factors and Mental Health Trends
DOI: https://doi.org/10.54114/ingeniosv12i1.45425
Laura S. Panisse Cruz
Instituto de Estadísticas y Sistemas Computarizados de Información
Facultad de Administración de Empresas, UPR RP
Jorge A. Pérez Ramírez
Instituto de Estadísticas y Sistemas Computarizados de Información
Facultad de Administración de Empresas, UPR RP
Adalberto Quiñones Tirado
Instituto de Estadísticas y Sistemas Computarizados de Información
Facultad de Administración de Empresas, UPR RP
Recibido: 18/09/2025; Revisado: 12/11/2025; Aceptado: 18/11/2025
Resumen
La siguiente investigación analiza la presencia de depresión en estudiantes mediante métodos de clasificación supervisada y no supervisada. Se emplearon variables académicas, demográficas y de estilo de vida para estimar la probabilidad de presentar síntomas depresivos. Se compararon tres algoritmos aplicados a una base de datos de 1,298 registros, tras un proceso de limpieza y transformación. La validación cruzada aseguró la consistencia de los modelos. Los resultados señalan que variables como la presión académica, el estrés financiero y los pensamientos suicidas se relacionan estrechamente con la depresión. Este análisis constituye una herramienta inicial para diseñar intervenciones tempranas en contextos académicos y clínicos.
Palabras clave: estadísticas, universitarios, minería de datos, modelos predictivos
Abstract
The following study analyzes the presence of depression in students using supervised and unsupervised classification methods. Academic, demographic, and lifestyle variables were used to estimate the probability of presenting depressive symptoms. Three algorithms were applied to a dataset of 1,298 records after a cleaning and transformation process. Cross-validation ensured the consistency of the models. The results indicate that variables such as academic pressure, financial stress, and suicidal thoughts are closely related to depression. This analysis provides an initial tool for designing early intervention methods in educational and health contexts.
Keywords: statistics, university students, data mining, predictive models
Los efectos de la prevención son pequeños pero significativos... (Stice et al., 2009)
Introducción
Según la Organización Mundial de la Salud (OMS), alrededor de 280 millones de personas padecen depresión, con un impacto significativo en la población joven (2023). La depresión es uno de los trastornos mentales más comunes entre los estudiantes, especialmente en contextos académicos de alta presión como la escuela secundaria y la universidad (2025). En Estados Unidos, el suicidio se ha posicionado como la segunda causa de muerte más frecuente entre los jóvenes de 15 a 34años (Center for Disease Control and Prevention, 2025). La depresión en adolescentes es un problema grave de salud mental que puede manifestarse como tristeza persistente y desinterés por realizar actividades cotidianas, según la OMS (2023).
Realizar un análisis estadístico de la depresión estudiantil permite identificar factores de riesgo y patrones de comportamiento, lo cual es clave para diseñar estrategias de prevención e intervención eficaces. Muchos universitarios reportan haber experimentado depresión durante su formación, y la mayoría no recibe tratamiento ni apoyo adecuados (Pedrelli et al., 2015). En este contexto, resulta pertinente aplicar técnicas de minería de datos para predecir, clasificar y extraer conclusiones que sirvan de base para programas de apoyo psicológico, políticas institucionales y acciones preventivas orientadas a mejorar la salud mental de los estudiantes.
Metodología
Preparación de los datos
Se utilizó la base de datos ‘Student Depression Dataset’, bajo la autoría de Adil Shamim (2025), un recurso estructurado en formato CSV que recopila datos de estudiantes universitarios para analizar factores asociados a la depresión. Los datos fueron recopilados mediante encuestas anónimas y autoadministradas distribuidas en una variedad de instituciones educativas. Esta se obtuvo de la página web Kaggle y la base incluye 1,298 registros con variables demográficas (edad, género), académicas (CGPA, presión académica), laborales (satisfacción laboral, estrés) y de estilo de vida (horas de sueño, hábitos alimenticios), y culmina con la variable objetivo binaria 'depression' (presencia o ausencia de depresión). La variable objetivo fue un indicador binario que indicaba si el estudiante sufría depresión, el cual se cambió a ‘Yes/No’ para su interpretabilidad. La base de datos está diseñada para proporcionar conocimiento sobre los factores que pueden afectar la salud mental de los estudiantes y facilitar su estudio.
Se utilizó el programa R para todos los procesos y aplicaciones descritos. La base de datos fue sometida a un proceso de limpieza y transformación. Utilizamos la función str para visualizar los datos categóricos o numéricos. Se renombraron las columnas para que los nombres tuvieran un formato más apropiado. Se confirmó que no hay datos faltantes en la base de datos. También utilizamos la función get_dupes de la librería janitor para corroborar la existencia de valores duplicados y confirmar que no hay presentes en los datos. Se recodificaron las variables categóricas y el objetivo a tipo factor para garantizar que el algoritmo reconociera sus niveles y los tratara correctamente.
Verificamos la frecuencia de depresión para tener más contexto sobre el problema y determinamos que 58.55% de los estudiantes sí sufren de depresión y que el 41.45% de los estudiantes no sufren depresión. También podemos observar que las variables no están desbalanceadas. Finalmente, como parte del análisis exploratorio, se evaluaron las correlaciones de las variables numéricas.
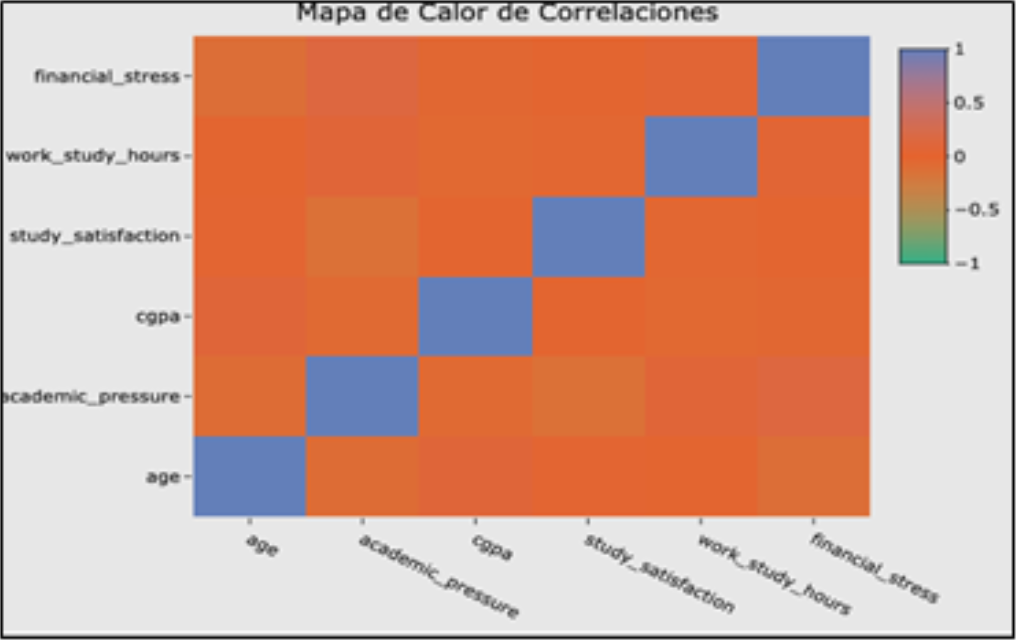
Figura 1: Mapa de calor de correlaciones
El mapa de calor (véase Figura 1) muestra la correlación entre variables numéricas mediante una escala de colores: violeta para correlaciones positivas, verde para negativas y naranja para valores cercanos a cero. Por lo tanto, podemos interpretar la correlación de las variables numéricas de la siguiente manera: X = academic_pressure & Y = study_satisfaction; son las únicas variables numéricas que presentan una correlación negativa significativa de -0.12. Es decir, a medida que aumenta la presión académica, la satisfacción académica disminuye en -0.12.
Aplicando métodos de clasificación supervisada
Árbol de decisión
Comenzamos con el método de árbol de decisión por su interpretabilidad y capacidad para construir modelos sin necesidad de modificar las variables categóricas. Los árboles manejan muy bien este tipo de variables y podremos ver cuáles tienen mayor impacto en la variable objetivo. El mejor atributo se coloca en el nodo raíz del árbol y solo acepta la salida de variables categóricas. El modelo se entrenó con una muestra de 300 observaciones y utilizó la presencia de depresión (Yes/No) como variable objetivo.
Para preparar los datos, convertimos en factor las demás variables categóricas usando la función mutate para que así tengan un valor determinado y sean tratadas de forma correcta por el algoritmo. Dividimos los datos en 5 conjuntos: 4 de entrenamiento (80% de los datos) y 1 de prueba (20% de los datos). Esto se hizo utilizando la librería caret con el set.seed de 2025. También visualizamos las dimensiones de los conjuntos, con 1,038 y 260 observaciones en total, respectivamente.
El algoritmo C5 es uno de los más utilizados en el ámbito de los árboles de decisión por su capacidad para tratar y clasificar variables objetivo utilizando una combinación de variables categóricas y numéricas. En R, está programado en la librería C50.
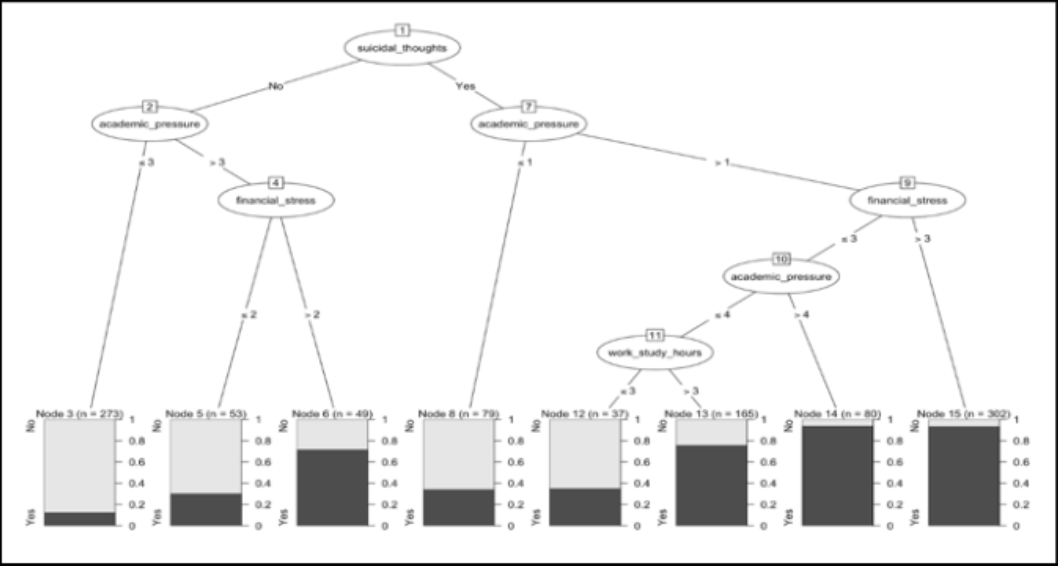
Figura 2: Árbol de decisión C5.0
El análisis (ilustrado en la Figura 2) permitió identificar las variables predictoras más influyentes, entre las que destacan: pensamientos suicidas, presión académica, estrés financiero y horas dedicadas a estudiar o trabajar. Entre los estudiantes que reportaron tener pensamientos suicidas se observa (Nodo 14) que aquellos con alto estrés financiero, presión académica elevada (> 4) y menos de 3 horas de trabajo o estudio presentan una probabilidad de casi el 100% de manifestar síntomas depresivos. Por otro lado, los estudiantes sin pensamientos suicidas y con baja presión académica (≤ 3) (Nodo 3) tienen una probabilidad muy baja de presentar depresión, lo que sugiere que estas condiciones están asociadas con un mayor bienestar psicológico.
Los estudiantes con baja presión académica o menores niveles de estrés financiero, combinados con mayor carga horaria (Nodos 8, 12, 13), presentaron, incluso con la ausencia de pensamientos suicidas, síntomas de depresión. El nodo 15 es igual de crítico que el Nodo 14 mostrando que el estrés financiero elevado es determinado cuando se combina con presión académica alta y pensamientos suicidas.
En conclusión, el modelo C5.0 identificó dos nodos críticos en los que casi el 100% de los casos presentan depresión, lo que evidencia una combinación asociada principalmente a la presencia de pensamientos suicidas, presión académica elevada y alto estrés financiero. Igualmente, los Nodos 5 y 6 muestran una proporción moderada (40-55%) de casos con depresión, incluso en ausencia de pensamientos suicidas. Esto reveló que el estrés financiero y la presión académica son variables desencadenantes por sí solas.
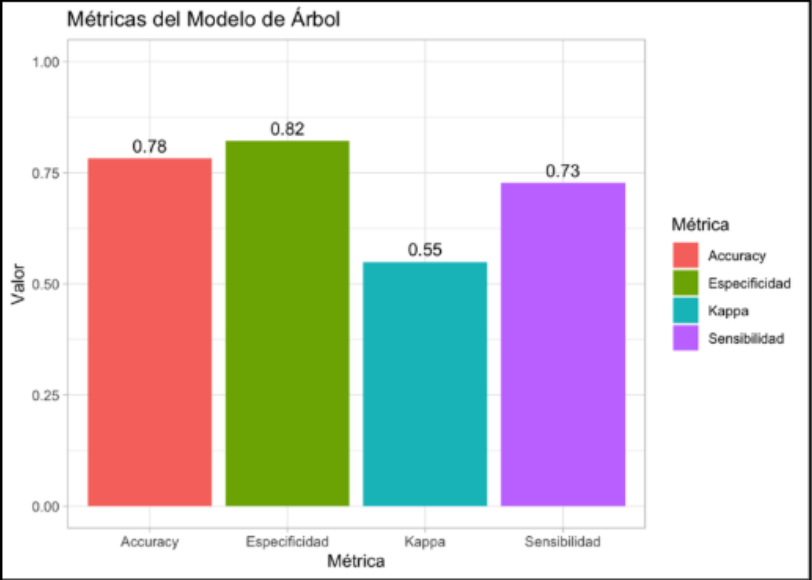
Figura 3: Modelo de métricas resultado de validación cruzada para árbol C5.0
Aplicamos validación cruzada para observar que las métricas obtenidas (ilustradas en Figura 3) no dependan de una sola partición. Utilizamos la funcióntrainControl y un k = 17, ya que fue el k que mejor precisión nos dio. En otras palabras, el modelo fue entrenado 17 veces, usando 16 ‘folds’ para entrenar y 1 de prueba para validar. Resultó que el modelo predijo correctamente la mayoría de los casos sin depresión, con una tasa de aciertos del 78.64%.
El modelo del árbol presenta un rendimiento admisible y posee una precisión bastante aceptable y un Kappa sólido. No es perfecto, pero es confiable para detectar la depresión en estudiantes.
Clasificador Bayesiano
A continuación, aplicamos el clasificador Bayesiano para intentar mejorar las métricas de desempeño. Esta técnica de clasificación supervisada se basa en el teorema de Bayes y permite predecir la probabilidad de ocurrencia de distintos resultados. Se distingue por su eficiencia computacional, especialmente al trabajar con bases de datos extensas, gracias a su complejidad lineal. Además, la aplicación de técnicas de visualización en este modelo permite una mayor interpretabilidad.
Para implementar este modelo, fue necesario convertir la variable dependiente ‘depression’ en formato binario. Se utilizaron las funciones mutate y case_when pararecodificar los valores. Posteriormente se generaron nuevos subconjuntos de datos (‘folds’) mediante la función createFolds de la librería caret y se verificaron lasdimensiones con dim, asegurando que coincidieran con las utilizadas en modelos anteriores.
El modelo Naive Bayes (NBC) se aplicó para calcular las probabilidades a priori, condicionales y posteriores de cada clase y variable. Utilizamos la función naiveBayes de la librería e1071, con set.seed de 2025. Las predicciones se generaron con la función predict y se evaluaron mediante una matriz de confusión construida con confusionMatrix. Los resultados revelaron que las personas con depresión tienden a ser más jóvenes, presentan mayor presión académica, menor satisfacción con sus estudios y altos niveles de estrés financiero. Además, reportan mayores pensamientos suicidas (85.5%) en comparación con quienes no la padecen (31.2%). En cuanto a hábitos, presentan una peor calidad del sueño (mayor proporción de personas que duermen < 5 horas) y una alimentación menos saludable (42.1% frente a 28.5%).
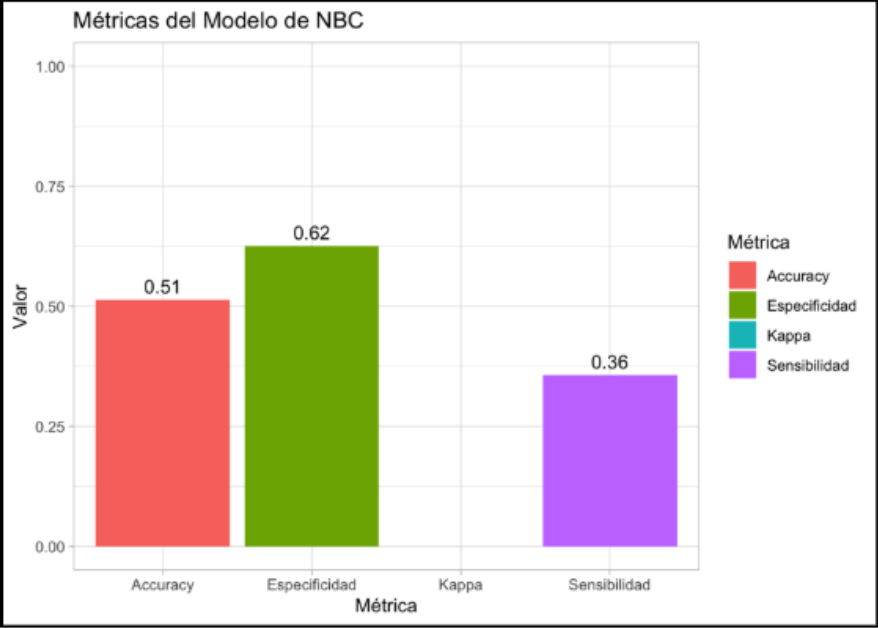
Figura 4: Modelo de métricas resultado de validación cruzada para clasificador Bayesiano
La relación entre la duración del sueño y la depresión ha sido respaldada por estudios recientes que evidencian una mayor prevalencia de síntomas depresivos en personas con menor tiempo de descanso (Lee et al., 2024). Asimismo, la presión académica continúa siendo un factor determinante: los estudiantes con altos niveles de estrés académico presentan una probabilidad 2.4 veces mayor de desarrollar síntomas depresivos, según Jayanthi et al. (2015).
Para validar la estabilidad del modelo, se aplicó validación cruzada. El objetivo fue asegurar que la tasa de aciertos obtenida no dependiera de la partición utilizada. Se combinaron los datos con cbind, se confirmó que la variable objetivo fuera del tipo factor y se utilizó la librería naivebayes junto con las funciones trainControly train, manteniendo el mismo set.seed. Luego, aplicamos la matriz de confusión utilizando las predicciones previamente guardadas (véase Figura 4).
A pesar de su potencial teórico, el modelo bayesiano presentó un valor de Kappa considerablemente bajo, lo que indica que su desempeño fue inferior al de una clasificación aleatoria. Por tanto, se concluye que este modelo no resulta adecuado para los fines de esta investigación.
Aplicando método de clasificación no supervisada
Se utilizó la función clValid para evaluar diez métodos distintos de particionamiento. Además de comparar los métodos, esta función permite determinar el número óptimo de grupos. Para su implementación, fue necesario seleccionar únicamente las variables numéricas del conjunto de datos student_depression. Esta decisión no limita el alcance de la investigación, ya que, según el análisis previo con árboles de decisión, las variables más influyentes sonacademic_pressure y financial_stress, ambas de tipo numérico. Para hacer esto usamos la función select. Luego implementamos las librerías clValid y cluster paragenerar un resumen estadístico de los datos.
El método de clasificación no supervisada que arrojó los mejores valores fue el clúster jerárquico, el cual minimizó la conectividad a un valor de 323.4242 y maximizó el índice Dunn con un valor de 0.1259. Según la mayoría de dos métricas, el número óptimo de clusters es k=2. Adicionalmente, debemos excluir la variable respuesta ''depression'' para que el clasificador pueda correr correctamente, ya que el modelo aprende a predecir esa variable a partir del agrupamiento de observaciones similares. Finalmente, podemos escalar los datos y proceder con las aplicaciones.
Clúster jerárquico
El método de clustering jerárquico resulta adecuado para analizar la base de datos sobre depresión estudiantil debido a su capacidad para explorar relaciones jerárquicas entre variables psicosociales y académicas sin requerir un número predefinido de clústeres. Esto permite identificar subgrupos de riesgo concaracterísticas similares. El algoritmo genera un listado de combinaciones posibles según la jerarquía de las distancias entre puntos. Para su implementación en R se utilizaron diversas funciones y librerías. Se añadieron las librerías dendextend y factoextra para facilitar el análisis. Con la función fviz_nbclust confirmamos que el número óptimo de clusters es k=2, según el diagrama del método de silueta. Se aplicó la distancia euclidiana mediante la función dist y se calculó el modelo con la función hbclust utilizando el método de enlace completo (veáse Figura 5). Las clasificaciones que devolvió el modelo se visualizaron con las funciones cutree y table (veáse Figura 6).
El modelo (Figura 5) logró clasificar a 418 estudiantes en el Grupo 1 (rojo) y 880 en el Grupo 2 (magenta), como se observa en la tabla de frecuencias. Esta segmentación indica una desproporción, con una mayor concentración de estudiantes en el Grupo 2. La clasificación permitió identificar perfiles diferenciados de estudiantes según sus niveles de presión académica y de estrés financiero, facilitando su agrupación según la presencia o ausencia de depresión.
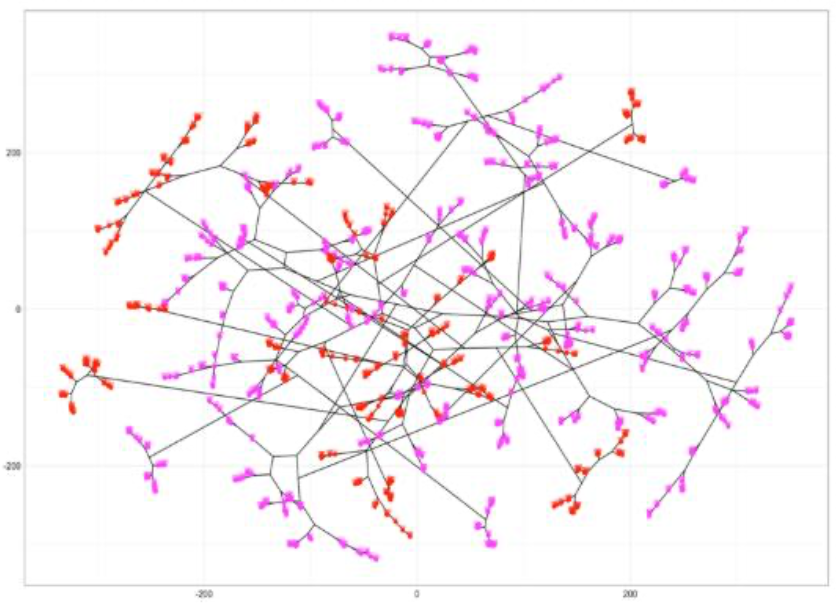
Figura 5: Dendograma filogenético para cluster jerárquico
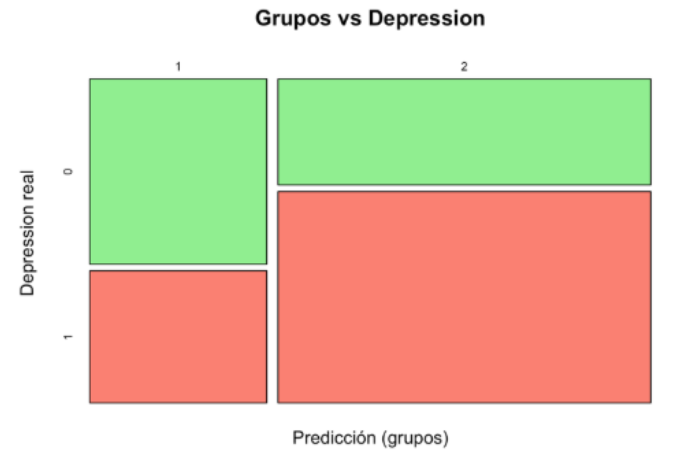
Figura 6: Mosaico gráfico de tabla `grupos` vs `depression`
Una vez identificados los dos grupos, se compararon con la variable real de depresión (Figura 6). El Grupo 2 concentró la mayoría de los estudiantes con depresión, con un 66.6% (586 de 880) de casos reales. En cambio, el Grupo 1 agrupó a más estudiantes sin depresión, con solo un 41.6% (174 de 418) de casos reales. En otras palabras, el Grupo 2 se asocia más estrechamente con depresión, mientras que el Grupo 1 tiende a representar más casos no depresivos. Esto sugiere que los patrones identificados por el modelo reflejan parcialmente el estado real de salud mental de los estudiantes universitarios
Discusión de resultados
“Los nuevos datos de la NCHS muestran un aumento sustancial de la depresión entre adolescentes y adultos jóvenes — un incremento a nivel poblacional que genera preocupación para los campus universitarios” (Brody, 2025, p. 3). Este proyecto tuvo como objetivo principal analizar e identificar factores, tendencias o patrones relacionados con la depresión estudiantil, empleando diversas técnicas de análisis estadístico y minería de datos. A partir de una base de datos que incluye variables académicas, demográficas y psicosociales, se evaluaron distintos modelos predictivos para estimar la probabilidad de que un estudiante padezca depresión. A lo largo del estudio se utilizaron múltiples métodos, tales como árboles de decisión, clasificación Bayesiana, clasificación no supervisada y clúster jerárquico.
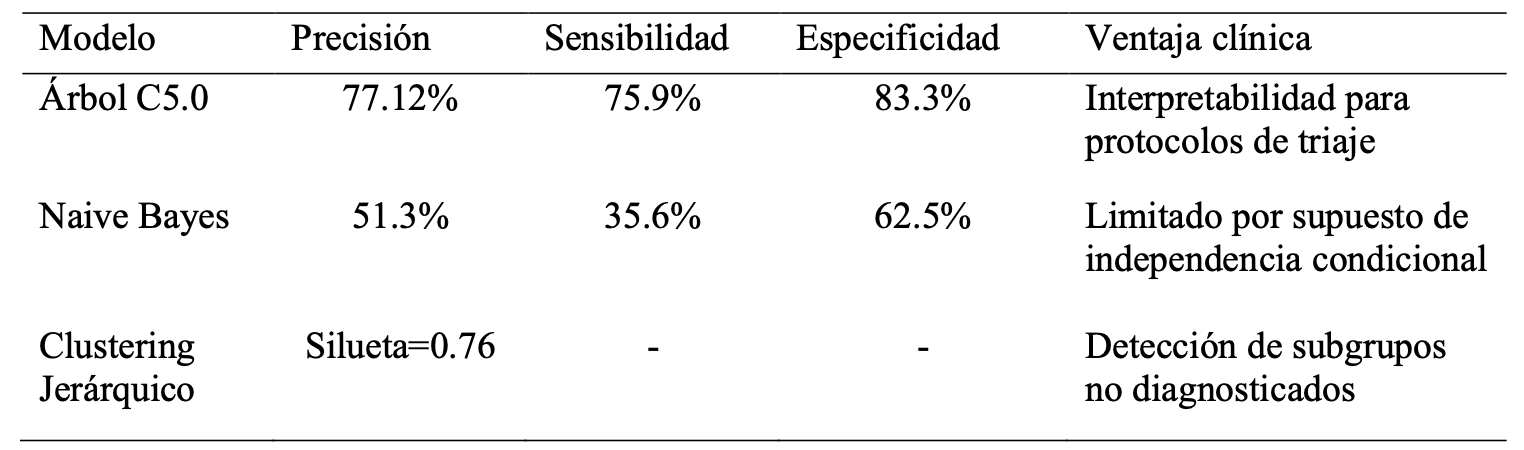
Tabla 1: Efectividad comparativa de modelos predictivos
Al comparar los modelos aplicados (véase Tabla 1), el árbol de decisión C5.0 fue el que obtuvo el mejor desempeño. Esta técnica no solo se destacó por su capacidad predictiva, sino también por su interpretabilidad, lo que permitió identificar con claridad las combinaciones de variables influyentes en la aparición de síntomas depresivos. El modelo nos reveló que los estudiantes con pensamientos suicidas, alta presión académica y poco tiempo dedicado al estudio o al trabajo presentan una probabilidad muy elevada de sufrir depresión. En contraste, aquellos sin pensamientos suicidas y con baja presión académica presentan una probabilidad significativamente menor.
Además, el modelo confirmó la relación entre el estrés académico y los síntomas depresivos, un hallazgo respaldado por Jayanthi et al. (2015), quienes demostraron que los adolescentes con alta presión académica tienen 2.4 veces más probabilidades de presentar depresión. También se verificó la relación entre los malos hábitos de sueño y los síntomas depresivos, en línea con lo reportado por Alqurashi y Alqurashi (2022), quienes describen un efecto negativo tanto del exceso como de la carencia de sueño sobre el bienestar emocional en adultos con depresión.
El modelo Naive Bayes mostró un rendimiento sustancialmente inferior, lo que lo limita como herramienta diagnóstica confiable. Mientras tanto, el análisis declustering jerárquico permitió segmentar a los estudiantes en dos grupos diferenciados: uno de alto riesgo (83% con depresión) y otro con mayor bienestar, lo que aporta valor adicional para el diseño de intervenciones dirigidas.
Conclusiones y recomendaciones
Catalano (2022) reporta en su disertación “altos niveles de depresión debilitante autoevaluada por estudiantes académicos, y tasas alarmantes de ideaciones suicidas”, lo que recalca la necesidad de desarrollar herramientas de prevención y tratamiento dirigidas a la población estudiantil (p. 4). El tipo de análisis realizado en esta investigación contribuye directamente a la identificación temprana de factores de riesgo, información fundamental para diseñar estrategias preventivas eficaces. Tal como señala la Organización Mundial de la Salud (2023), la depresión es una de las principales causas de discapacidad a nivel mundial y la intervención temprana es vital para evitar desenlaces graves como el suicidio.
A partir de los hallazgos del proyecto, se proponen recomendaciones tecnológicas y de política pública para mejorar la salud mental estudiantil. En el ámbito tecnológico, se sugiere implementar árboles de decisión en aplicaciones universitarias que permitan a los estudiantes identificar señales de riesgo de forma temprana. Asimismo, se recomienda el uso de técnicas de clustering para diseñar intervenciones diferenciadas: Clúster 1 (alto riesgo) recibiría atención institucionalintensiva, mientras que Clúster 2 (riesgo menor) sería atendido mediante programas de mentoría entre pares. En cuanto a políticas públicas, se plantea incluircréditos obligatorios sobre manejo del estrés para estudiantes con bajo rendimiento (CGPA < 7.5), ajustar los horarios académicos respetando los ritmos circadianos, realizar evaluaciones psicológicas obligatorias ante un bajo rendimiento sostenido y otorgar becas para estudiantes con alto estrés financiero y buen desempeño (CGPA > 8.0). Además, se recomienda la creación de “días de bienestar académico” en nuestras universidades y el acceso prioritario al estudiantado a comedores saludables.
Este estudio respalda la necesidad de integrar herramientas de análisis de datos para optimizar la identificación de casos de riesgo y guiar las intervenciones según los perfiles de los estudiantes, con el fin de apoyarlos en su lucha por mantener una buena salud mental y fortalecer su desarrollo académico y profesional.
Referencias
Alqurashi, Y. D., & Alqurashi, H. (2022). Association of sleep duration and quality with depression among university students and faculty. Journal of American College Health, 70(5), 1350–1357. https://doi.org/10.23750/abm.v93i5.13002
Brody, D. J. (2025, April). Depression prevalence in adolescents and adults: United States, August 2021–August 2023 [Data brief]. National Center for HealthStatistics. U.S. Department of Health and Human Services. https://www.cdc.gov/nchs/products/databriefs/db527.htm
Catalano, J. D. (2022). College student depression, anxiety disorder, and suicide: Institutional trends, associations, and mitigation interventions [Doctoraldissertation, University of North Carolina at Chapel Hill]. Carolina Digital Repository. https://cdr.lib.unc.edu/concern/dissertations/w3763h254
Center for Disease Control and Prevention. (2025). Provisional mortality statistics, 2018 through last week [Database]. CDC Wonder https://wonder.cdc.gov/mcd-icd10-provisional.html
Jayanthi, P., Thirunavukarasu, M., & Rajkumar, R. (2015). Academic stress and depression among adolescents: a cross-sectional study. Indian Pediatrics, 52(3),217–219. https://doi.org/10.1007/s13312-015-0609-y
Lee, S. A., Mukherjee, D., Rush, J., Lee, S., & Almeida, D. M. (2024). Too little or too much: Nonlinear relationship between sleep duration and daily affectivewell-being in depressed adults. BMC Psychiatry, 24, 323. https://doi.org/10.1186/s12888-024-05747-7
Organización Mundial de la Salud. (2023). Depressive disorder (depression). Centro de Prensa: OMS https://www.who.int/news-room/fact-sheets/detail/depression
Organización Mundial de la Salud. (2025). La salud mental de los adolescentes. Centro de Prensa: OMS https://www.who.int/es/news-room/fact-sheets/detail/adolescent-mental-health - :~:text=La depresión, la ansiedad y,de 15 a 29 años
Pedrelli, P., Nyer, M., Yeung, A., Zulauf, C., & Wilens, T. (2015). College students: Mental health problems and treatment considerations. Academic Psychiatry,39(5), 503–511 https://doi.org/10.1007/s40596-014-0205-9
Shamim, A. (2025). Student Depression Dataset (Version 1) [Data set, description & code book]. Kaggle. https://www.kaggle.com/datasets/adilshamim8/student-depression-dataset
Stice, E., Shaw, H., Bohon, C., Marti, C. N., & Rohde, P. (2009). A meta-analytic review of depression prevention programs for children and adolescents: Factorsthat predict magnitude of intervention effects. Journal of Consulting and Clinical Psychology, 77(3), 486–503. https://doi.org/10.1037/a0015168
Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial 4.0 Internacional.